If there’s a place where Google needs to respect its own Google guidelines, Search Console help should probably be the first one, since it’s where Google is providing recommendations….
That said, I’ll show you this is not all the time the case.
The problem:
If you’re searching today for « your money your life google site:google.com » in Google.ch, you’ll probably find a Google Search Console help page returned as shown below.
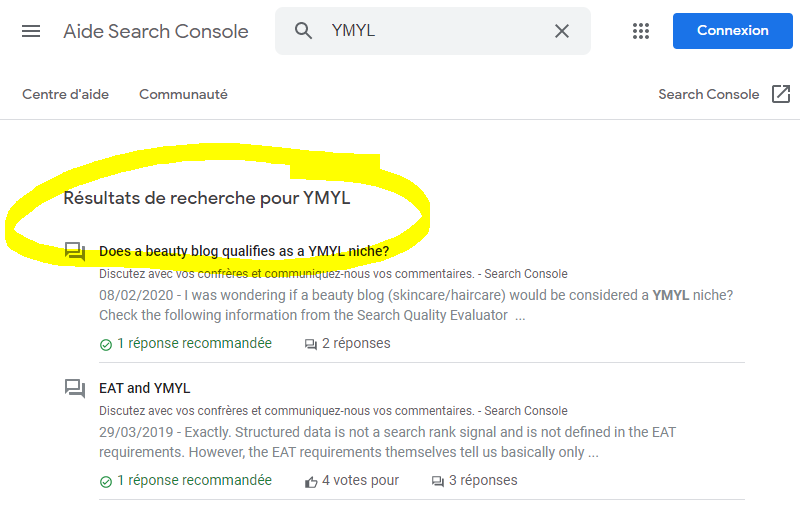
Surprisingly, this is an internal search results page from the Google Webmaster website: https://support.google.com/webmasters/search?q=YMYL
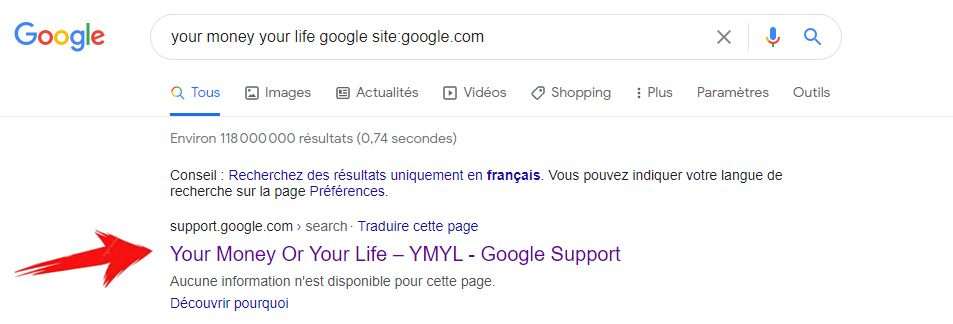
For sure, we may think Google allows to index its own search results and this is strictly against the Official Google Guidelines:
Don’t let your internal search result pages be crawled by Google. Users dislike clicking a search engine result only to land on another search result page on your site.
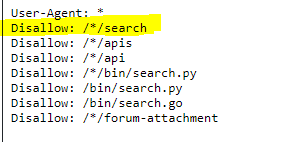
But in fact Google looks to not do this indexation… As you can see below, the Robots.txt file is properly set and disallow any search page indexation :
And, Google is setting correctly the Meta Robots value to « noindex,nofollow » in the HTML of the search page…

So, what’s wrong and why Google looks to index its own internal search content?
We can see 2 possibilities :
First possibility: indexation signals are contradictory…
In fact, we need to dig a bit more to detect the HTML of the page includes a Canonical Link…
This is exactly what Google is asking to not do… Google’s John Mueller advises site owners not to mix signals like noindex and rel=canonical since these signals are contradictory pieces of information: « not indexing » and « index the content on a specific URL ».
Most of the time, Google will pick rel=canonical over noindex in cases where both signals are being used. This is the reason why we can see such very unexpected search results returned by Google.
But… as you can observe, the Canonical link is pointing to the main Search section page: https://support.google.com/webmasters/search?hl=fr … That creates an unexpected situation because Google won’t « normally » have access to this page (Robots.txt restrictions)… So a possible scenario is Google will understand the page needs to be indexed but since Google is « stucked in the middle », the algorithm won’t follow the initial Canonical tag directive, and finally, decide to index the search page with the initial URL…
Second possibility: Google won’t respect Robots.txt
Google can decide to not follow the Robots.txt restrictions. This is what Google explains on this page: https://developers.google.com/search/docs/advanced/robots/intro?hl=en .
- A robotted page can still be indexed if linked to from other sites
While Google won’t crawl or index the content blocked byrobots.txt, we might still find and index a disallowed URL if it is linked from other places on the web. As a result, the URL address and, potentially, other publicly available information such as anchor text in links to the page can still appear in Google search results. To properly prevent your URL from appearing in Google Search results, you should password-protect the files on your server or use the noindex meta tag or response header (or remove the page entirely).
So, if Google finds external links to a « robotted » page, Google will crawl the page, store & analyze the content and use it to construct the search result…
We can also imagine a scenario in which there’s an original external link (on a page removed by Google) but redirected (302 or 301) to a this internal search help page…
Solutions
To fix this issue, the Google Webmaster Help team needs to remove the Canonical tag to avoid Google algorithm conflicts, be « Google compliant » and clean the search results.
But, since Google may not be able to crawl again this page (Robots.txt disallow) the Google Search team should be able to clean and remove all « Ghost » indexed search results pages by using the Search Console removal tool and ask to remove all URL with the path « https://support.google.com/webmasters/search?q= »
Conclusion
« Doing SEO » and trying to be « Google compliant » is not something easy. Part of the SEO job is very technical and most of the time you’ll have to find an accurate expertise to deal with.
Florian Bessonnat
https://www.linkedin.com/in/florian-bessonnat-9a6a3a3/
Any feedback or questions, please feel free to contact me on Linkedin.
Updated: 28/01/2021 19:28